研发质量管理中的 MTTR、MTBF、MTTF、MTTD 都是什么?今天我们从生产事件的全生命周期出发,认识研发质量管理的 9 个度量指标——「MT 家族」。
01 Mean Time To ALL
「MT」是 Mean Time 的缩写,意为平均时间,「MT 家族」则是 LigaAI 对「MT」开头的一系列量化指标的戏称。
最常用于跟踪研发质量的两个 MT 指标分别是 MTTR 和 MTBF。近几年,随着精细化研发管理需求的攀升,行业也出现了 MTTD、MTTA、MTRS、MTTI 等细分管理指标,旨在帮助技术团队更好地了解生产事件发生的频率以及团队的恢复速度。
02 共识在前,度量在后
在使用「MT 家族」度量质量水平之前,研发团队需要先就两个基础问题达成共识。
- 如何计算系统的总服务时长?
- 如何定义系统的可用时间(Uptime)和不可用时间(Downtime)?
明确第一个问题有助于规范讨论对象。系统的服务周期是多长?系统维护升级或提前告知的主动停机等特殊事件应否计入服务时长?研发团队应就以上问题达成一致,才能辅助更准确的度量和管理。
讨论第二个问题的意义在于建立内部一致的判断标准。什么样的事件属于完全中断事件?在部分中断事件中,多大程度的阻碍或多大影响范围的故障可以被定义为「系统不可用」?可正常运行但不符合预期水平的系统是否处在可用状态?
如果能将事件的具体量值和标准讨论并确定下来,研发效能管理或许会有一个更加清晰的视图。
03「MT 家族」全员辨析
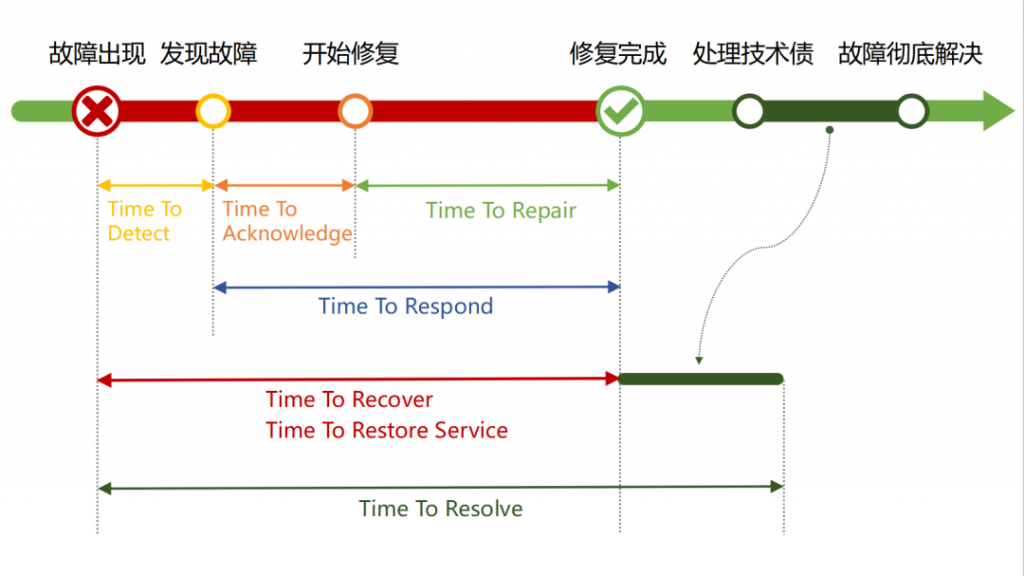
下面是单个生产事件从故障发生到修复完成的简要示意图,根据起止时间点的不同,我们将获得若干个 MT 指标。
温馨提示:研发效能管理下的「MT 指标」或与其他领域的定义有所不同。
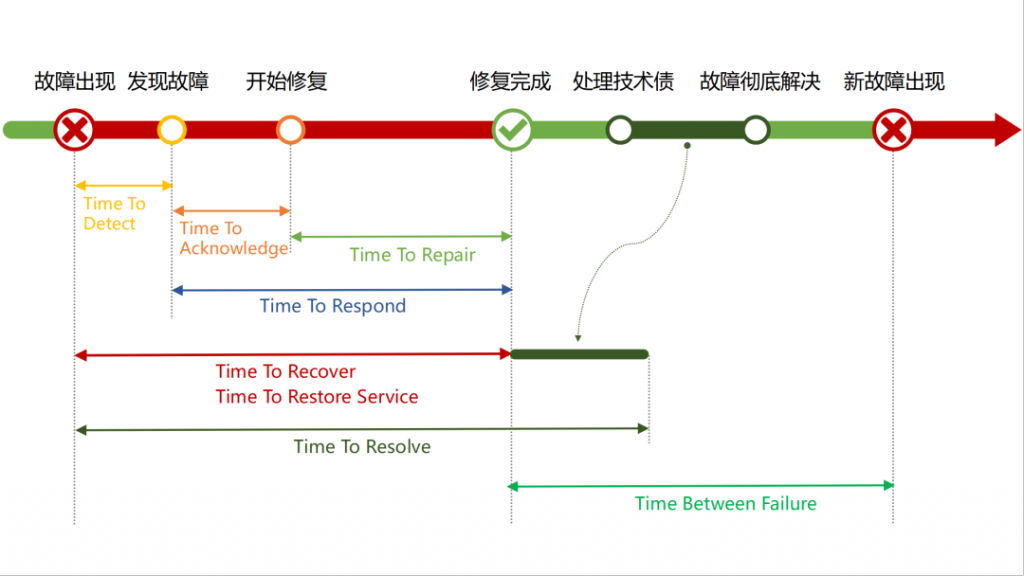
1. Mean Time To Detect(MTTD)
平均故障检测时间(MTTD)是系统出现故障到问题首次被发现的平均时间,用来衡量问题在被发现前存在的平均时长,可以用一定周期内的事件总检测时间除以事件总个数计算得出。
系统出现故障后,生产事件可能会被监控工具或观测平台快速识别并自动提醒,也可能被用户率先发现。因此,对问题识别得越慢,MTTD 越大,用户可能遭受中断的时间也会越长。
2. Mean Time To Acknowledge(MTTA)
平均应答时间(MTTA)衡量了系统不可用被首次发现后,研发团队平均需要多久能够着手修复问题,反映了团队的响应能力和警报系统的效率。定期监控 MTTA 对减少警报噪音,提高工作效率也有显著作用,因为居高不下的 MTTA 可能说明研发团队正在被「警报疲劳」所困扰。
MTTA = 故障首次被发现到开始修复的总间隔时间/事件总数
3. Mean Time To Repair(MTTR)
根据「R」的不同释义,MTTR 可以表示为平均修复时间、平均恢复时间、平均响应时间和平均解决时间。四者在含义上皆有不同,因此在日常工作和沟通中,要小心上下文缺失导致的「鸡同鸭讲」哦!
平均修复时间衡量了研发团队排除和修复故障的效率,是指开发团队从开始修复到系统恢复正常运行的平均时间,包含修复、测试、部署等多个环节。
平均修复时间可以用一定周期内的系统总修复时长除以事件总个数得出。MTTR 越小,说明系统的可维护性越强,易恢复性越好。此外,由于系统复杂情况或故障严重程度各不相同,技术管理者在实际管理中也要避免掉入「数字管理陷阱」。
MTTR = 开始修复到恢复可用状态的总间隔时间/事件总数
4. Mean Time To Recover(MTTR)
平均恢复时间也称平均服务恢复时长(Mean Time To Restore Service, 即 MTRS),也是 DORA 指标中的「服务恢复时间」。
它衡量了系统从不可用状态恢复到正常可用状态的平均耗时,在数值上与系统的平均不可用时长相等,包含研发团队监控、定位、识别和解决故障等多个过程。经验法则指出,优秀的研发团队每年的平均恢复时间一般不超过 5 个小时。
MTTR 或 MTRS = 系统总不可用时间/事件总数
5. Mean TimeTo Respond(MTTR)
平均响应时间是指系统不可用状态从被发现到被解决的平均时间,反映了研发团队响应需求和变化的效率以及系统可维护性的高低。平均响应时间不考虑事件通知的延迟性,常在网络安全中用来衡量团队缓解系统攻击的效率。
MTTR = 故障被发现到系统恢复可用的总间隔时间/事件总数
6. Mean Time To Resolve(MTTR)
平均解决时间衡量了故障出现到被彻底解决所花费的平均时间。「彻底解决」意味着该故障在未来的运行中不会再现,因此平均解决时间需要统计研发团队发现问题、检测故障、修复故障以及确保故障不会再发生等环节的总时间。
MTTR = 故障出现到彻底解决的总间隔时间/事件总数
7. Mean Time Between Failure(MTBF)
平均无故障时间(MTBF)是衡量系统可靠性和可用性的关键指标之一,指可修复系统在运行期间从前一个故障(结束)到下一个故障(出现)所经历的平均时间,代表了系统的平均可用时间。
MTBF 越大,说明系统持续提供正确服务的时间越长,可靠性越强。通过计算一定周期内的 MTBF,研发团队还可以对未来故障的发生时间展开预测,以便更好地管理。
MTBF = 连续两次事件的总间隔时间/事件总数
8. Mean Time To Failure(MTTF)
与 MTBF 相似,平均失效时间(MTTF)也是衡量系统可靠性的关键指标;二者的区别在于,MTTF 用于衡量不可修复的系统,而 MTBF 的管理对象是可修复的系统。
MTTF 是指不可修复的系统或产品从开始运行到发生故障而终止服务的平均时间,可以简单理解为平均使用寿命。相比软件研发行业,MTTF 更常用来描述硬件、组件或基础设施等等。

其管理价值在于通过对大量相同类型的系统或产品进行更长周期的观察和统计,团队可以了解该类型系统/产品的失效时间,并率先为淘汰和更换旧系统/产品做好准备。
写在最后
速率、质量和价值是研发效能管理的三驾马车。而相较速率而言,研发质量管理对团队共识的要求更高,因为我们需要通过集思广益,描绘一个线条干净、指标区隔清晰的质量评估视图,以进一步支持无歧义的指标量化管理;否则,研发效能管理最终又会回到让人头疼的「定义讨论会」。
本文所提到的 9 个「MT 指标」可以从系统可靠性、可用性和可维护性等多个维度,衡量研发质量水平并辅助技术管理者展开更精确、更精准的研发质量监控和管理,进而有效提升组织效能,赋能业务增长。
>> LigaAI 往期精彩阅读 <<
技术分享 | 如何编写同时兼容 Vue2 和 Vue3 的代码?
了解更多开发者提效、研发效能管理、前沿技术等消息,欢迎关注 LigaAI。欢迎体验我们的产品,期待与你一路同行!