编者按:
软件工程师所做的事情就是把现实中的事情搬到计算机上,通过信息化提高生产力。在这个过程中有一个点是不能被忽视的,那就是[系统的内建质量]
设计良好的系统: 概念清晰,结构合理,即使代码库庞大,依然可理解、可维护;
设计糟糕的系统: “屎上雕花”。
其中,领域概念和领域模型的缺失是造成这种差异的罪魁祸首。
>> 概念解读
领域驱动设计 – DDD(Domain-Driven Design)是一种基于领域知识来解决复杂业务问题的软件开发方法论,其本质是将业务上要做的一件大事,经过推演和抽象,拆分成多个内聚的领域。
它有以下三个重点:
- 跟领域专家(Domain Expert)密切合作来定义出Domain的范围及解决方案
- 切分领域出数个子领域,并专注在核心子领域
- 透过一系列设计模式,将领域知识转换成对应的程序模型(Model)
领域可大可小,对应着大小业务问题的边界,对边界的划分与控制是领域驱动设计强调的核心思想。
>> DDD带来的改变
向Anemic Model 说 “No!”
跟大家介绍一个有名的反模式:贫血模型(Anemic Model)。此模式泛指那些只有 getter与 setter 的 model。这些 model 缺乏行为表述,导致使用者每次都要自己组合出想要的功能。
“贫血模型使用起来像在教小孩子一样,一个指令一个动作还很容易忘掉;具有行为表述能力的模型则像跟大人沟通一样,一次行动就能完成许多指令。”
举个栗子:以数据为中心的方式是要求客户代码必须知道如何正确地将一个待定项提交到冲刺中。此时,错误地修改sprintId或有另外一个属性需要设值,都要求开发人员认真分析客户代码来完成从客户数据到BacklogItem属性的映射。这样的模型不是领域模型。
public class BacklogItem extends Entity {
private SprintId sprintId;
private BacklogItemStatusType status;
...
public void setSprintId(SprintId sprintId) {
this.sprintId = sprintId;
}
public void setStatus(BacklogItemStatusType status) {
this.status = status;
}
...
}
// 客户端通过设置sprintId和status将一个BacklogItem提交到Sprint中
backlogItem.setSprintId(sprintId);
backlogItem.setStatus(BacklogItemStatusType.COMMITTED);通过业务语言封装程序行为
DDD注重将业务语言引入程序模型之中,对重点业务行为进行封装。与其随意封装代码,将程序模型与业务逻辑绑定在一起的行为可以保证代码紧随业务变化做出调整。在建模时,领域专家讨论了以下几个需求:
- 允许将每一个待定项提交到冲刺中且只有在一个待定项位于发布计划(Release)中时才能进行提交
- 如果一个待定项已提交到了另外一个冲刺中,先将其回收
- 提交完成时,通知相关客户方
客户代码并不需要知道提交BacklogItem 的实现细节,因为实现代码的逻辑恰好能够描述业务行为。
public class BacklogItem extends Entity {
private SprintId sprintId;
private BacklogItemStatusType status;
...
public void commitTo(Sprint sprint) {
if (!this.isScheduledForRelease()) {
throw new IllegalStateException("Must be scheduled for release to commit to sprint.");
}
if (this.isComittedToSprint()) {
if (!sprint.sprintId().equals(this.sprintId())) {
this.uncommitFromSprint();
}
}
this.elevateStatusWith(BacklogItemStatus.COMMITTED);
this.setSprintId(sprint.sprintId());
DomainEventPublisher.instance()
.publish(new BacklogItemCommitted(
this.tenantId(),
this.backlogItemId(),
this.sprintId()
));
}
}
// 客户端通过设置特定于领域的行为将BacklogItem提交到Sprint中
backlogItem.commitTo(sprint);>> DDD 详解
举例说明DDD:
假设我们现在在做一个简单的数据统计系统,其运算逻辑是这样的:地推员输入客户的姓名和手机号,系统根据客户手机号的归属地和所属运营商,将客户群体分组,分配给相应的销售组,由销售组跟进后续的业务。
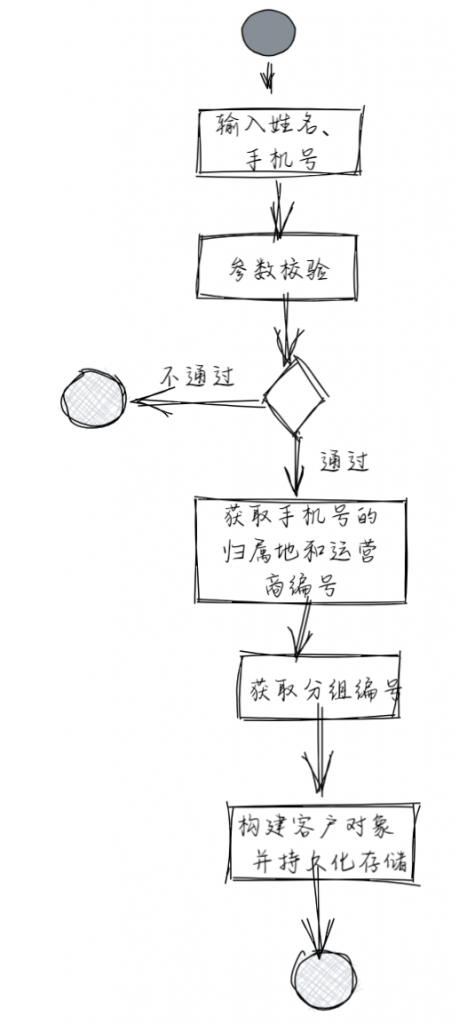
ublic class RegistrationServiceImpl implements RegistrationService {
private final SalesRepRepository salesRepRepo;
private final UserRepository userRepo;
public User register(String name, String phone) throws ValidationException {
// 参数校验
if (name == null "" name.length() == 0) {
throw new ValidationException("name");
}
if (phone == null "" !isValidPhoneNumber(phone)) {
throw new ValidationException("phone");
}
// 获取手机号归属地编号和运营商编号,然后通过编号找到区域内的SalesRep
String areaCode = getAreaCode(phone);
String operatorCode = getOperatorCode(phone);
SalesRep rep = salesRepRepo.findRep(areaCode, operatorCode);
// 最后创建用户,落盘,然后返回
User user = new User();
user.name = name;
user.phone = phone;
if (rep != null) {
user.repId = rep.repId;
}
return userRepo.save(user);
}
private boolean isValidPhoneNumber(String phone) {
String pattern = "^0[1-9]{2,3}-?\\d{8}$";
return phone.matches(pattern);
}
private String getOperatorCode(String phone) {
// TODO
}
private String getAreaCode(String phone) {
// TODO
}
}
代码如上,大部分人都是这么写的,看起来也没什么问题,对一个小工程或短期下线的系统来说,这样写可以称得上是又快又好;但把其放在一起迭代频繁的大工程内,还留有一些隐患:
隐患1:接口语义不明确
Register 方法的bug在于它支持一种类型、两组参数(用户名、手机号)。当用户注册系统的参数变更时,比如改用身份证注册,Register方法就要被改造为RegisterByPhone和RegisterByIdCard。由于内部校验只会保留参数类型不会保留参数名,因此变更参数意味着新的接口和再来一遍的校验,这不是我们预期的目标。我们期望的是:语义接口足够明确无歧义、可扩展性强且带有一定的自检性,这才是最优解。
接口语义修改目标:语义明确无歧义、扩展性强、带有一定的自检性
隐患2:参数校验逻辑复杂
如果存在多个类似的方法,每个方法都要在开头校验,一定会存在大量重复代码。一旦某个类型的参数校验逻辑需要修改,那么每个地方都要一一修改,这显然不符合“开闭原则”。即使将其封装进某个工具进行复用,还存留两个bug:1、在业务方法中把参数异常和业务逻辑异常混合起来,不太合理: 业务方法内还需要主动调用工具类来进行校验,如果校验失败,需要抛出异常;2、随着参数类型越来越多,工具类中的校验逻辑会随之不断膨胀,后续维护起来是不小的工作量。
参数校验修改目标:提高校验逻辑复用性参数校验异常与业务逻辑异常解耦
隐患3:核心业务逻辑清晰度不够
经过改造后的代码,虽然多了些优雅但不“纯粹“。RegistrationService 是用于对用户进行注册的服务,它的职责应仅限定为「注册」。而注册最本质的行为就是「拿到用户的信息并存储起来」。在这段代码中存在的两个行为「获取手机号的归属地编码」、「获取运营商编码」显然并不适用于「注册」这个业务逻辑。
问题来了:那我们为什么要在Register方法里边写这些逻辑?为了适配findRep这个接口来对原始的参数进行处理拼接,就像拿胶水来进行缝缝补补的“胶水逻辑”?
如何改造这些“胶水逻辑”才合理?
两个思路:
1、改造 findRep 这个接口的入参
这在抽象上就是合理的,不必在register方法内进行胶水操作了
2、把「获取手机号的归属地编码」&「获取运营商编码」内聚到手机号
这个类型中这两个行为都是获取手机号相关的属性,内聚在手机号这个类型中在抽象上也是合理的。
由此看来,采用内聚、搭建核心领域编辑的方法能使注册方法逻辑最为清晰。
什么逻辑应该归属于哪个业务域,这是对“领域“的理解,就像如何对微服务进行边界限定一样,不同的理解角度会产生不同的领域模型划分。
需要说明一点:很多同学对写单元测试感到头疼:写的话,要做到高覆盖很麻烦;不写的话,不仅跑不过CI,心里还有点慌……不怕!通过对PhoneNumber逻辑的内聚、业务逻辑的简化,童鞋们写单元测试的效率能够得到极大的提升。PhoneNumber 这类型的改动频率比较小,一旦写了完善的测试用例,复用程度会很高~这样,后边的业务逻辑尽管会变复杂,但单元测试逻辑的维护成本也不会提高~
领域驱动设计不是某一种具体的流程方法,它是由核心概念、语义方法,经过实战演练后被证明可以举一反三,事半功倍的软件开发方法论。经它验证过的案例不胜枚举,后续我们将就一则新的案例讨论其背后的语言逻辑和行为方法~
领域驱动设计入门与实践[上]