不同领域对国际化的定义各不相同,这里谈论的是 W3C 国际化活动材料的高级工作定义。有些人使用其他术语(例如全球化)来指代同一概念。
国际化是产品、应用程序或文档内容的设计和开发,它可以为不同文化、地区或语言的目标受众轻松实现本地化。国际化(Internationalization)通常用英文写成i18n,其中 18 是英文单词中i和n之间的字母数。[1]
本文主要基于java,针对语言国际化进行阐述。任何一个面向全世界的软件都会面临多语言国际化的问题,对于java web应用,要实现国际化功能,就是在数据展示给用户之前,替换成用户可识别的语言。
1.使用spring自带的i18n(国际化)
这部分比较简单,在网上搜索就可以找到教程,这里将会手动配置一次spring i18n国际化来介绍一下。以下是笔者使用的spring boot版本号。

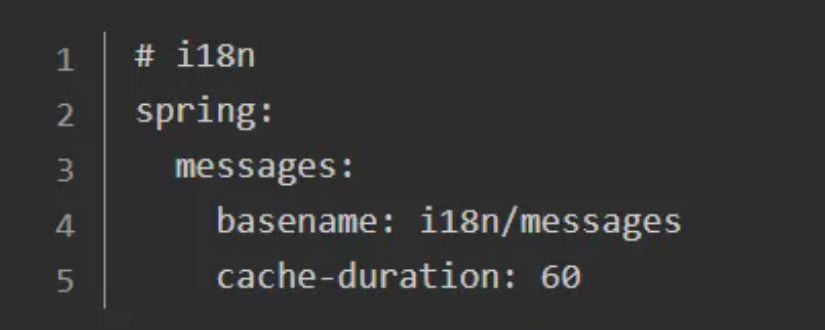
1-1.在properties或yml资源文件里面配置i18n
笔者用的是yml文件,可以自行转换成properties文件格式。
basename:以逗号分隔的基名列表(本质上是一个完全限定的类路径位置),每个基名都遵循 ResourceBundle 约定,对基于斜杠的位置提供宽松的支持。如果它不包含包限定符(例如 “org.mypackage” ),它将从类路径根目录解析。
cache-duration:加载的资源包文件缓存的持续时间。如果没有设置,捆绑包将被永久缓存。如果没有指定持续时间后缀,将使用秒。
1-2.在resources文件夹下新增i18n文件夹,并新建相应的国际化文件
spring容器启动的时候,会根据配置的basename去对应的路径加载资源文件到MessageSource里,至于是怎么加载到MessageSource里的,在这里就不展开阐述了。
文件配置如图 1-1所示。
注意:红色框里的就是i18n资源文件的配置,绿色框是idea自动生成的文件夹,实际并不存在,无视就行。
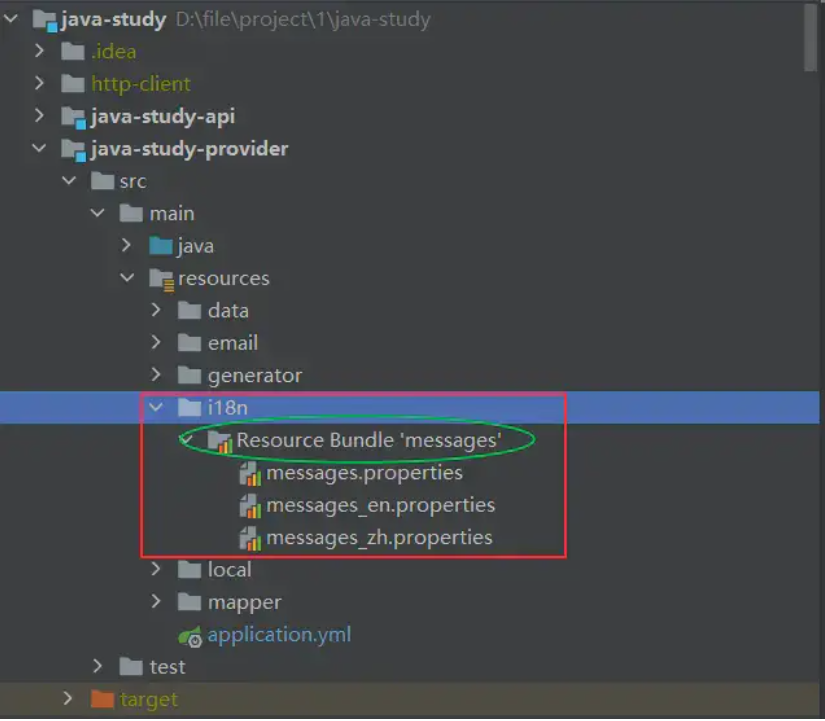
图 1-1 i18n资源文件.png

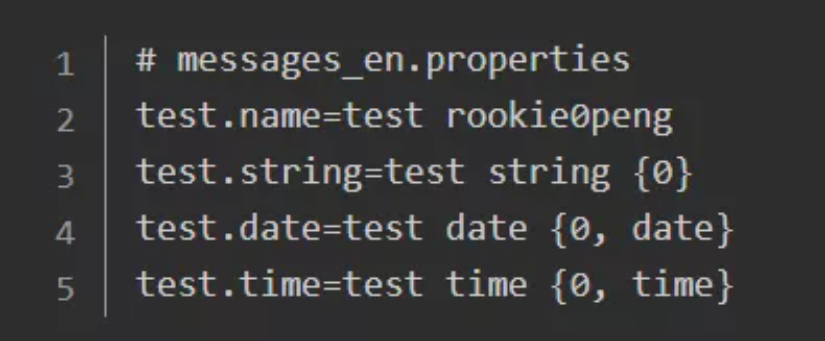
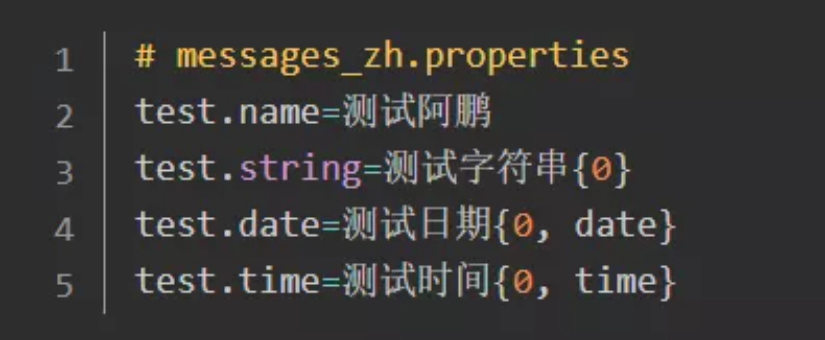
1-3.在代码中使用i18n进行国际化
这里演示的是比较简单的手动参数替换,还有更好一些的方法,比如在响应数据写入流的时候进行参数替换。
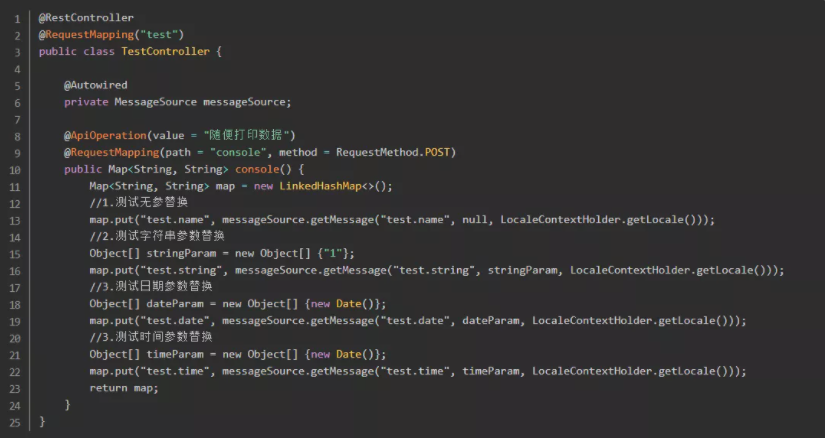
1-4.测试spring i18n
启动项目后,查看调用/test/console 接口返回的数据,调用三次,分别设置header中的语言:默认、中文、英文。
笔者用的是idea的HTTP Client,以下是请求参数:
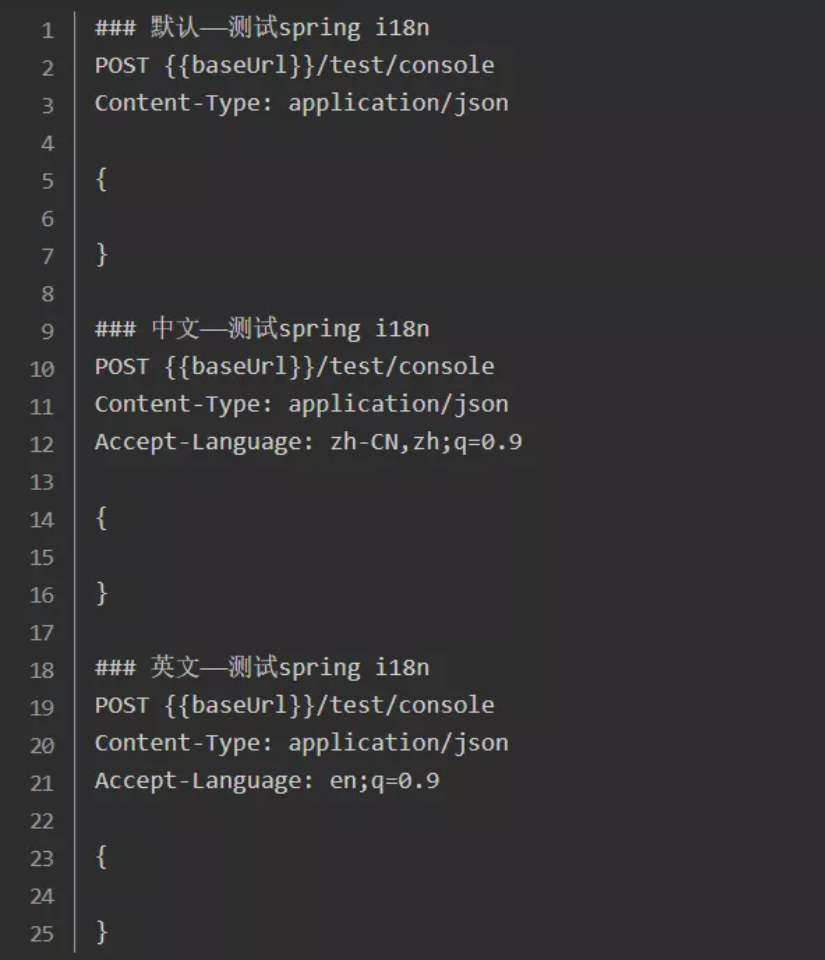
以下是响应参数:
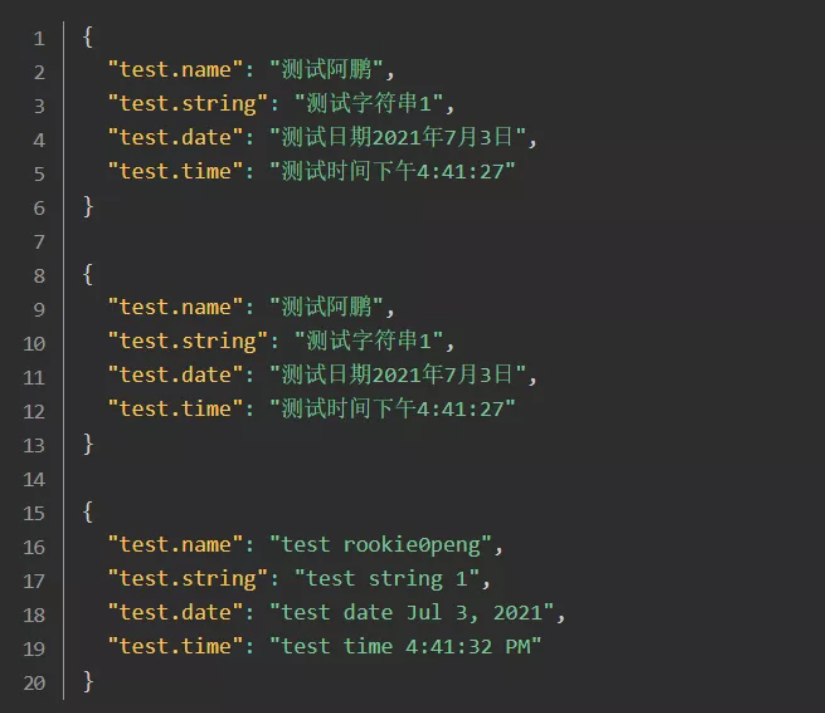
1-5.分析执行结果
1-5-1. 测试默认和测试中文的响应数据是一样的,可以确定系统默认使用的中文环境。
1-5-2. 调用 getMessage() 方法时,不传第2个参数就是无参替换;否则,反之。
1-5-3. 使用有参替换时,还可以在 properties 文件里加入 date、time 等参数,spring 可以自动格式化成对应的日期和时间。
1-6.结论
这里只是简单的演示了spring i18n的功能,可以满足一些简单场景的需求,如果需要进行扩展的话,有几种思路。
1-6-1. 如果使用了 nacos 等配置中心,则需要去注册中心手动拉取i18n的 properties 文件内容,并加载到应用程序的内存里,也可以在本地用户文件夹存放一份。
1-6-2. 如果需要一些正则翻译的话,则需要自己动手写正则替换的表达式。
1-6-3. 该例子展示的是在controller里进行替换,更好一点的方式是在filter,甚至是在响应数据写入流的时候进行替换,比如说指定某个响应对象的某个属性的序列化类(@JsonSerialize(using = TestJsonSerializer.class)),则该字段序列化的时候,就会使用TestJsonSerializer.class进行序列化。在这个类里面就可以针对性地做我们想要的替换了。
2.自定义i18n
spring i18n的功能较为好用,但是面对复杂的业务需求,还不够强大。比如,用户想添加一种语言;递归替换;布局可以自定义,用户添加布局字段时,针对该项目或组织的不同地区的人员,设置不同的翻译内容等等。
基于各种各样的原因,扩展i18n已是必须要做的事。那么怎么扩展呢?
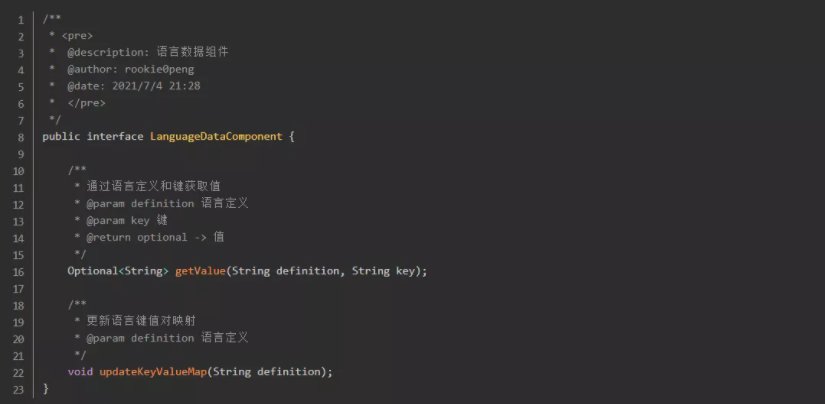
国际化的本质就是将 key 替换成不同语言的 value ,这句话中有几个关键点:key、替换、语言、value。其中 key 、语言、value 都是名词,代表着具体的数据;替换是动词,代表具体的翻译逻辑。那我们就需要针对这几个点进行设计与实现。
2-1.设计数据表
思路:通过一种语言和键找到对应的值。表结构设计比较简单,key、value、语言各建一个表,如图 2-1所示。

图 2-1 国际化表结构设计.png
其中每个表只展示了主键编号字段,其实还有一些字段没展示出来,比如 code、name,这些可以根据自己的风格去设计。如果是多租户的系统,在每张表后面加入对应的租户id,即可进行数据隔离。
2-1-1. 如果用户新增的字段需要翻译,往语言键里增加一条数据,以及往语言值里增加与语言定义相同数量的记录即可。
2-1-2. 如果用户新增语言定义,则往语言值里面增加与语言键相同数量的记录即可。
2-1-3. 更新、删除同理。
2-2.数据缓存设计
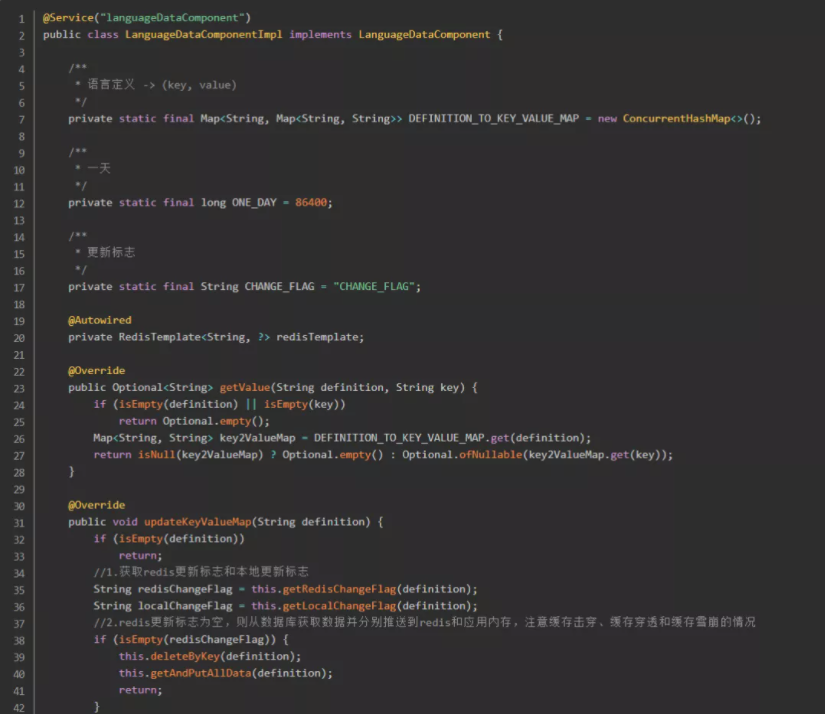
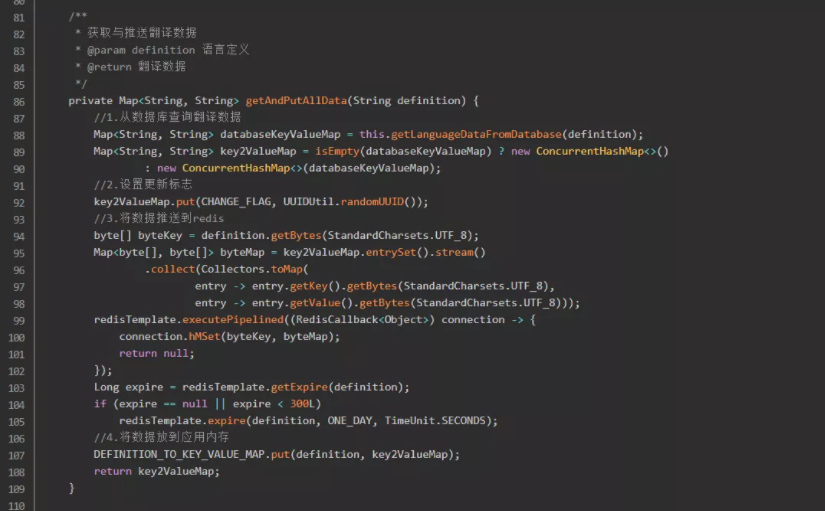
在一个面向世界的应用里面,翻译的频率是很高的,而且随着时间的流逝,翻译的数据肯定会越来越多,如果每次响应数据的翻译都去查询数据库的话,那势必会造成数据库性能以及应用本身性能的浪费。对于这种修改频率不算高的数据,咱们可以缓存起来,用空间换时间。这里打算用两级缓存的设计来适应该翻译场景,一级是redis,二级是应用内存。
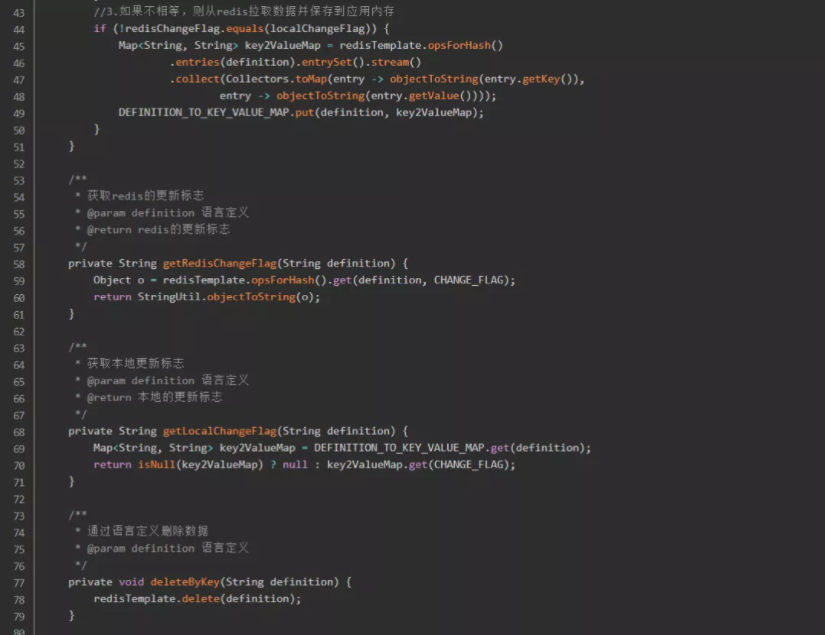
step1:将用到的数据从数据库缓存在redis里面,并且生成一个更新标志放入redis。应用获取翻译数据的时候先判断redis更新标志是否为空。
step2:若为空,则代表redis尚未缓存翻译数据,将翻译数据从数据库拉取到内存,且推送到redis;若不为空,则代表redis已缓存翻译数据,然后再比对redis的更新标志和应用内存的更新标志是否一致。
step3:若不一致,则说明翻译数据已经改变,需要从redis重新拉取一次翻译数据,缓存在应用内存中;若一致,则说明翻译数据尚未改变,可以直接使用应用内存中的翻译数据。
step4:将最后拿到的翻译数据(key-value)返回给实现翻译逻辑的组件。
如图 2-2所示。
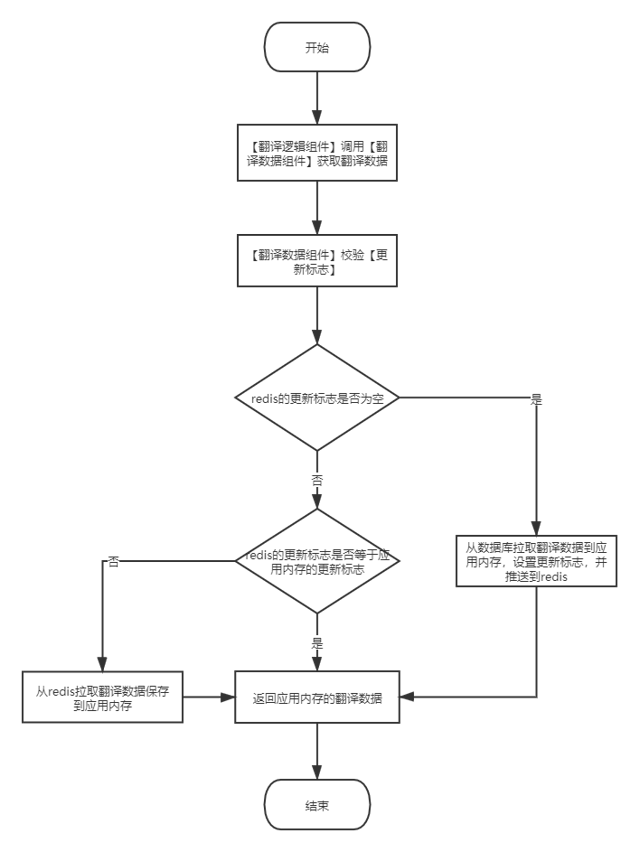
图 2-2 国际化两级缓存设计.png
代码如下所示。
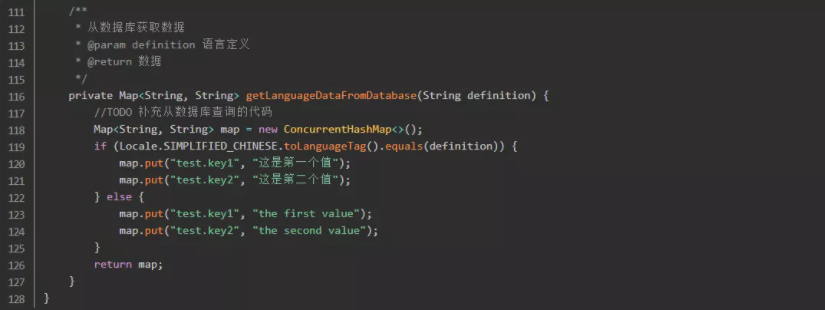
2-3.将替换逻辑嵌入spring的filter或者序列
笔者在这里只演示简单的key->value替换,至于递归替换、正则替换可以自行考虑加上。
A. 当一个请求进来的时候,首先需要做一些前置处理。
B.根据请求的语言设置当前线程的语言环境。
C.更新一次当前应用内存的语言缓存数据。
D.当返回响应的时候,通过序列化对响应数据进行替换。
代码如下所示。
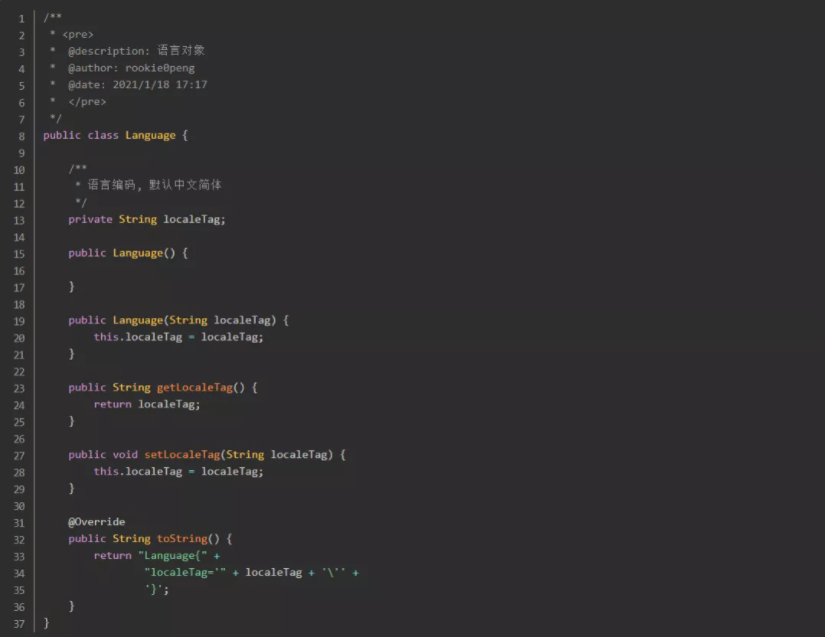
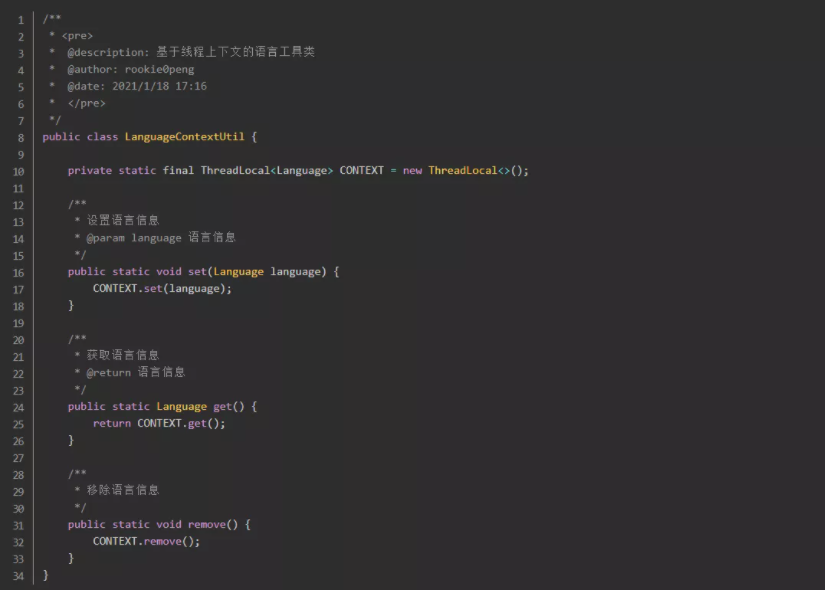
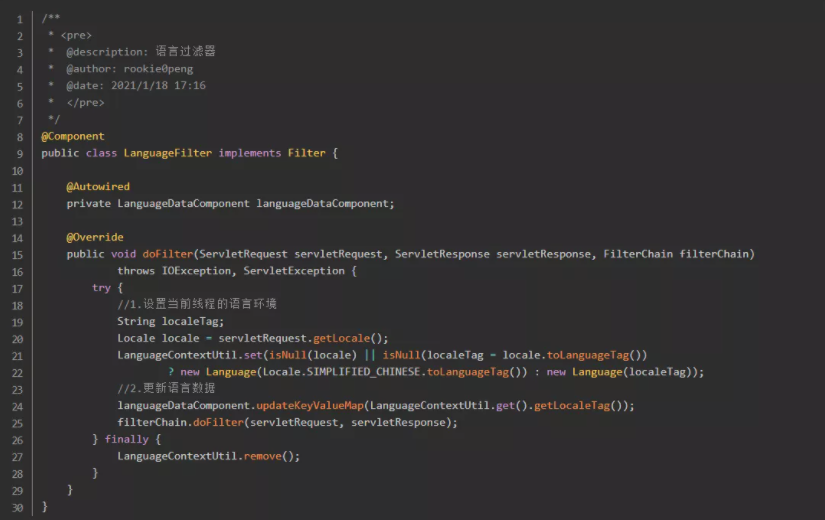
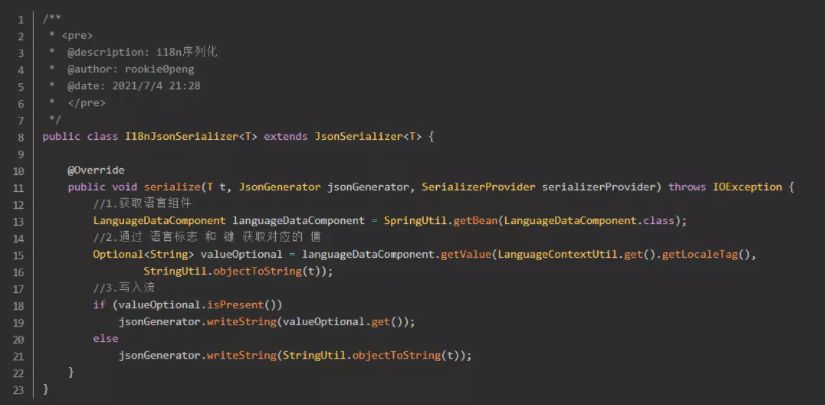
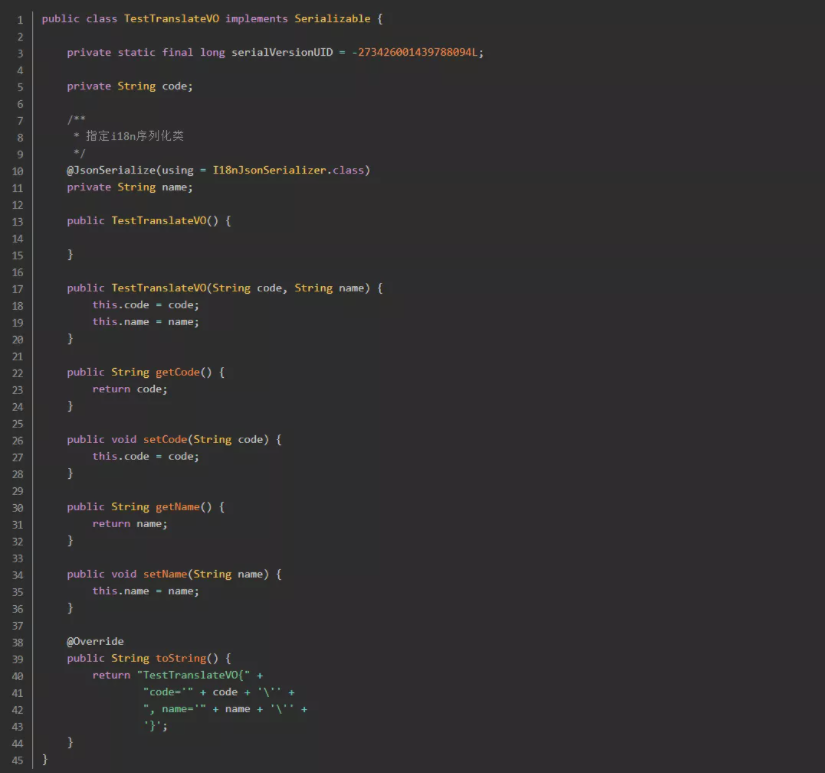
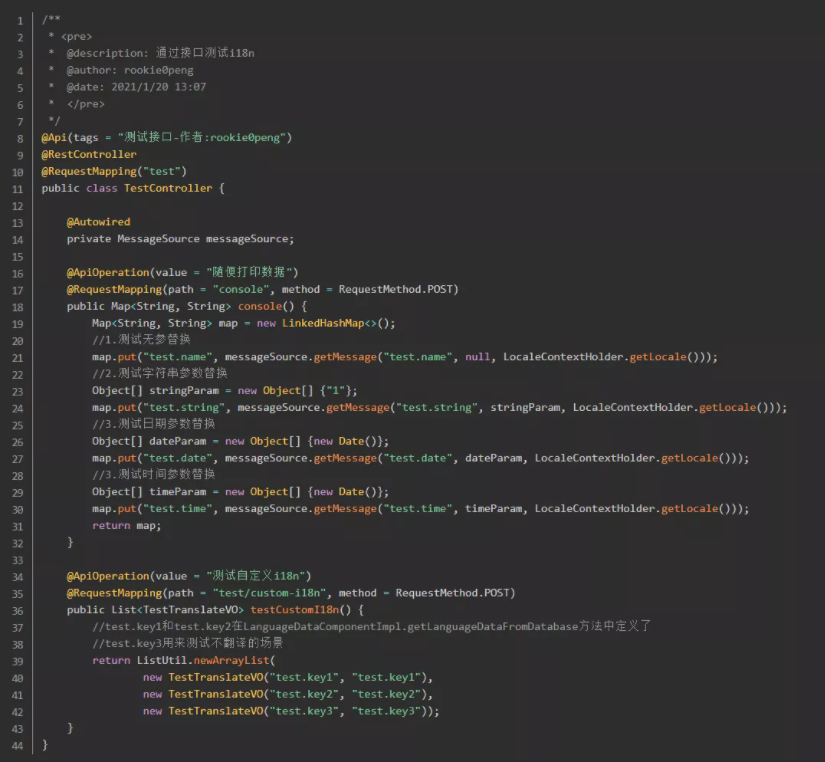
2-4.测试自定义i18n
启动项目后,查看调用 test/custom-i18n 接口返回的数据,调用三次,分别设置header中的语言:默认、中文、英文。
笔者用的是idea的HTTP Client,以下是请求参数:
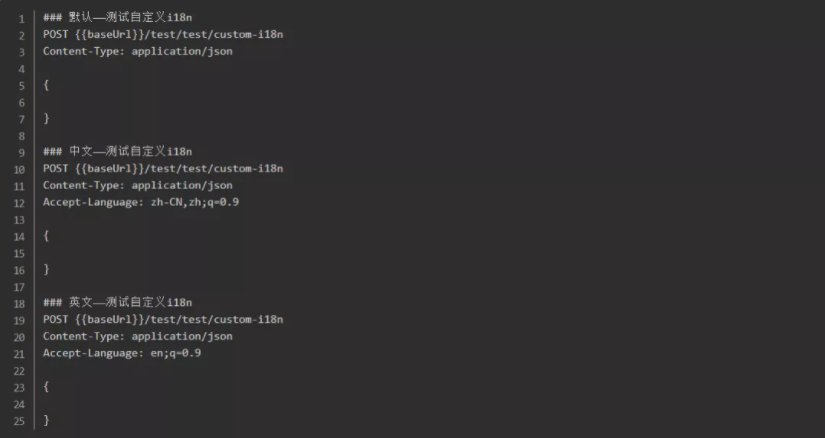
以下是返回参数:
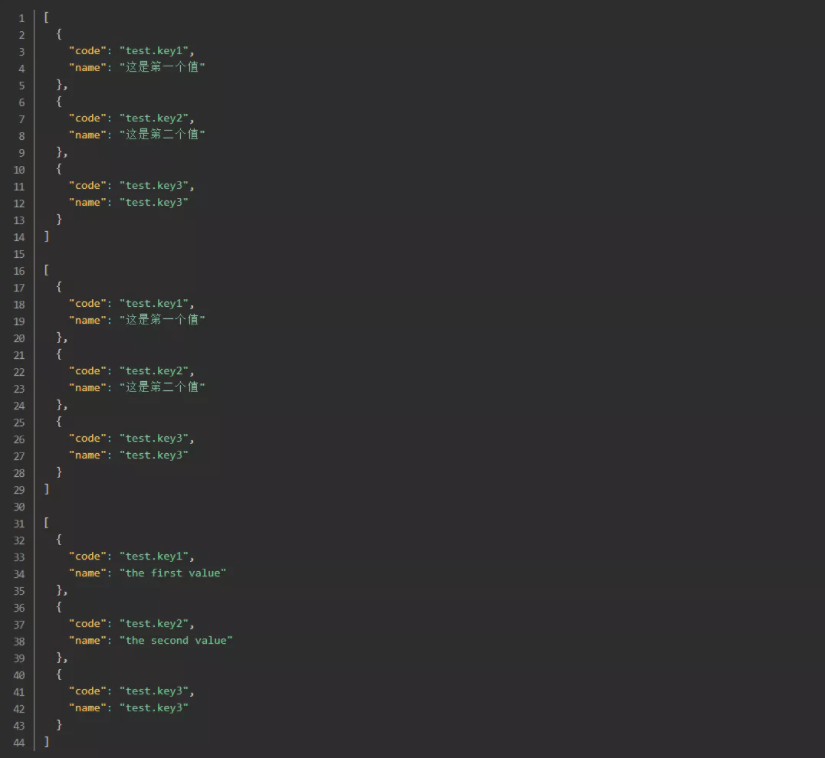
2-5.分析执行结果
- 2-5-1.测试默认和测试中文的响应数据是一样的,可以确定系统默认使用的中文环境。
- 2-5-2.对于使用了@JsonSerialize(using = I18nJsonSerializer.class)注解的属性,会根据key自动替换成对应的值。
- 2-5-3.根据key没找到值时,还是会使用原本的key。
2-6.结论
这里只是简单的演示了自定义i18n的功能,但是已然支持用户新增语言、自定义翻译后的值、多机部署等。如果想要支持正则替换、递归翻译也可以自行扩展。
3.总结
这里演示了两种i18n的实现方案,具体想用哪种就见仁见智了。图方便,开箱即用,那就选spring i18n;图灵活,可扩展性强,那就选自定义i18n。自然,肯定还有很多我没想到的方案,期待交流。
后续LigaAI会继续分享更多技术干货的文章,欢迎关注我们的官方网站 LigaAI-新一代智能研发管理平台~
[1] “Localization vs. Internationalization”.W3C
作者:rookie0peng
原文链接:https://www.jianshu.com/p/95e0f1df8edf
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!